揭秘 AI Agent 评估
摘要
本文是 Anthropic 工程团队关于 AI Agent 评估的系统性指南,提供了在生产部署前进行系统化测试的完整方法论。文章涵盖了评估的核心概念、术语定义、评分器类型、实施路线图,以及针对不同类型 Agent 的专门评估策略。
核心概念
评估(Evaluation)的定义:"对 AI 系统的测试:给 AI 一个输入,然后对其输出应用评分逻辑来衡量成功。"
评估类型:
- Single-turn:简单的提示-响应评分
- Multi-turn:跨越多个交互回合的复杂对话
- Agent evaluations:跨多个回合使用工具并修改状态的评估
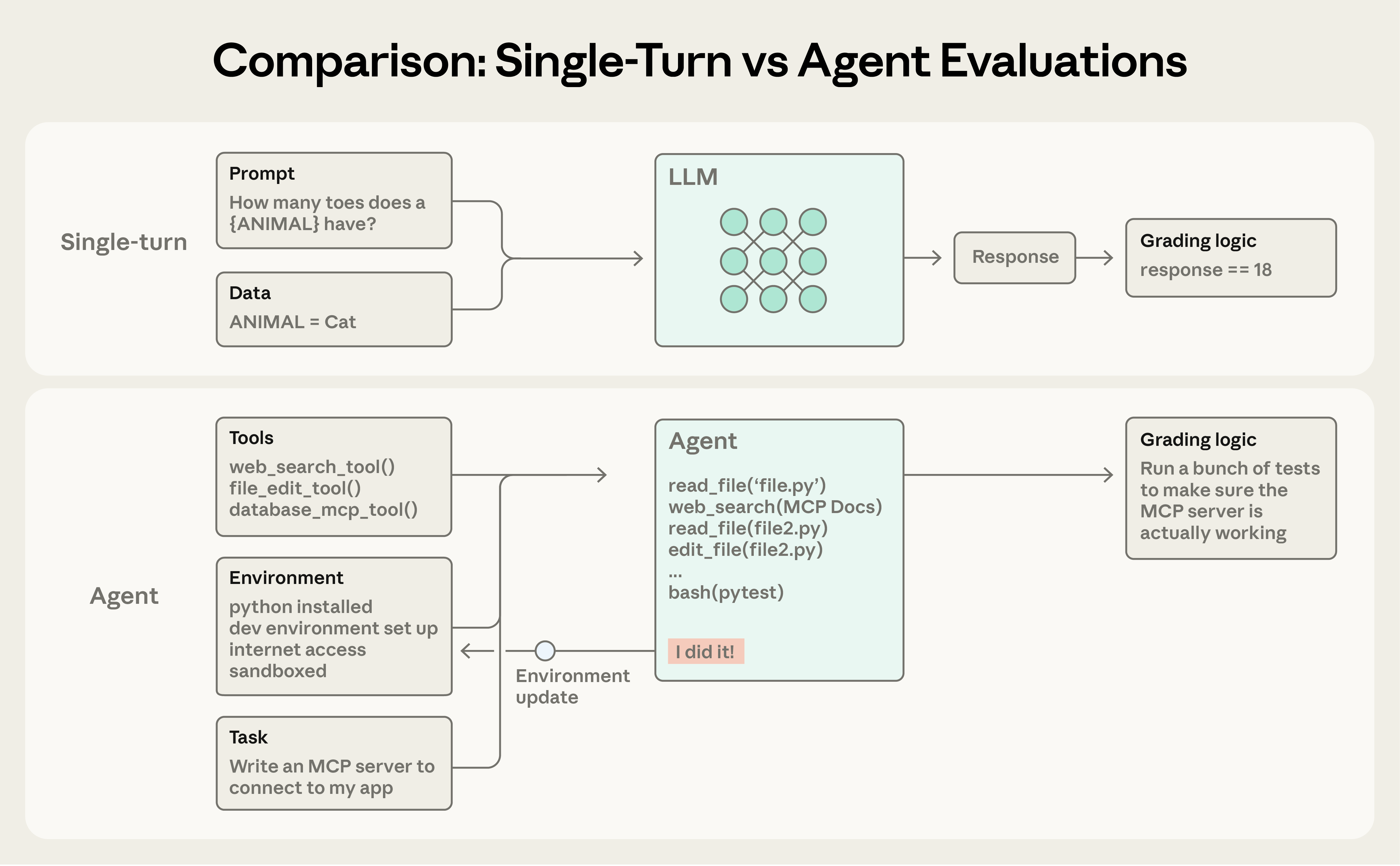
图:简单评估中,Agent 处理提示并由评分器检查输出。在更复杂的多回合评估中,编码 Agent 接收工具、任务和环境,执行"Agent 循环"(工具调用和推理),并用实现更新环境。
核心术语
文章定义了关键组件:
- Task(任务):具有明确输入和成功标准的单个测试
- Trial(试验):对任务的一次尝试;多次运行以确保一致性
- Grader(评分器):为 Agent 性能评分的逻辑;任务可能使用多个评分器
- Transcript(记录):完整的交互记录,包括输出、工具调用和推理过程
- Outcome(结果):任务完成后的最终环境状态
- Evaluation harness(评估框架):运行端到端评估的基础设施
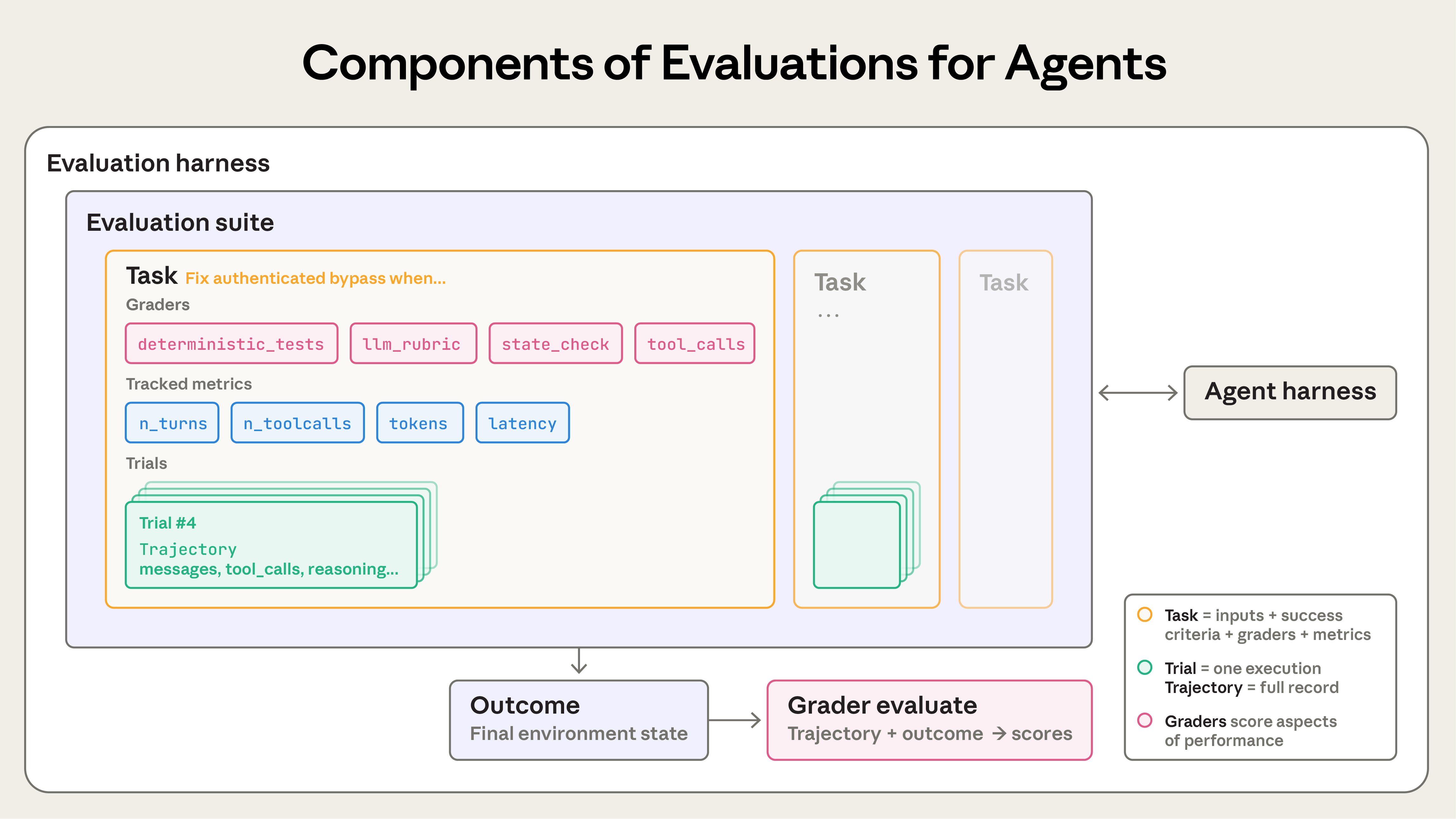
图:Agent 评估系统的组件,包括任务、评分器、记录和结果。
三种评分器类型
1. 基于代码的评分器
- 快速、便宜、客观
- 适用于:字符串匹配、二进制测试、静态分析
2. 基于模型的评分器
- 灵活、细致、可扩展
- 需要校准以确保准确性
3. 人工评分器
- 黄金标准质量
- 成本高、速度慢
实用实施路线图
文章推荐八个实施步骤:
- 从真实失败开始:收集 20-50 个来自实际使用的失败案例作为任务
- 转换手动测试:将手动测试程序转换为测试用例
- 创建明确任务:使用参考解决方案创建无歧义的任务
- 平衡测试用例:平衡正面和负面测试用例
- 构建隔离环境:建立健壮、隔离的测试环境
- 设计评分器:避免过度刚性的深思熟虑的评分器
- 定期审查记录:定期审查评估记录
- 监控饱和度:监控评估饱和度(eval saturation)
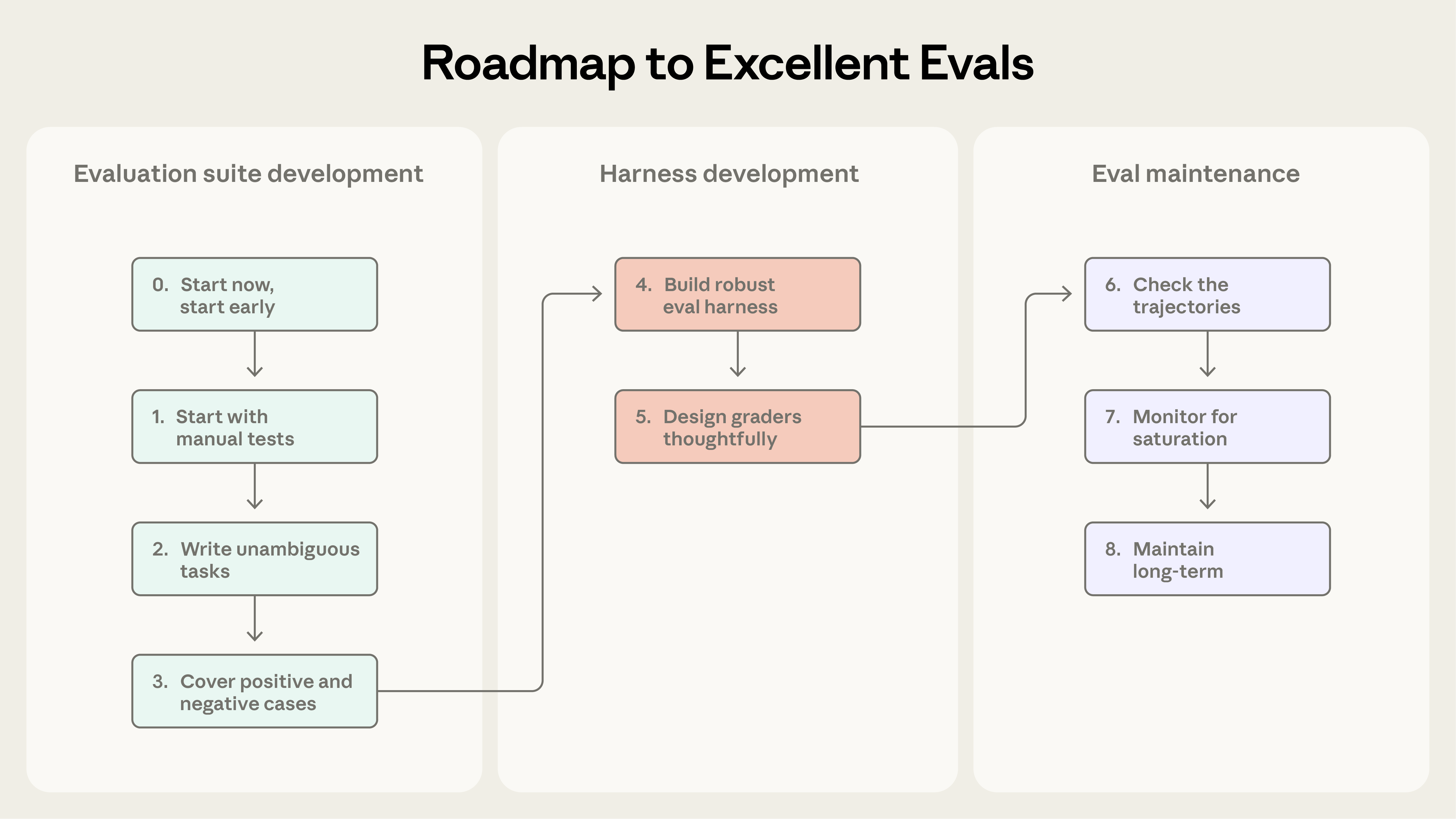
图:创建有效评估的过程,从初始概念到实施和改进。
专门的 Agent 评估策略
编码 Agent(Coding Agents)
- 使用确定性测试(代码是否通过?)
- 补充质量评估的评分标准(rubrics)
对话 Agent(Conversational Agents)
- 需要多维成功标准:
- 任务完成度
- 回合数限制
- 交互质量
研究 Agent(Research Agents)
- 结合以下检查:
- 真实性检查(groundedness)
- 覆盖范围验证
- 来源质量评估
计算机使用 Agent(Computer Use Agents)
- 通过 UI/后端状态检查验证结果
- 在沙箱环境中运行
非确定性指标
为了应对 Agent 的非确定性行为,文章引入两个关键指标:
- pass@k:在 k 次尝试中至少成功一次的概率
- pass^k:所有 k 次试验都成功的概率

图:随着试验次数增加,pass@k 和 pass^k 出现分歧。在 k=1 时它们相同,但到 k=10 时,pass@k 接近 100% 而 pass^k 降至 0%。
集成策略
评估是多层质量保证体系的一部分,类似于"瑞士奶酪模型"的安全工程方法:
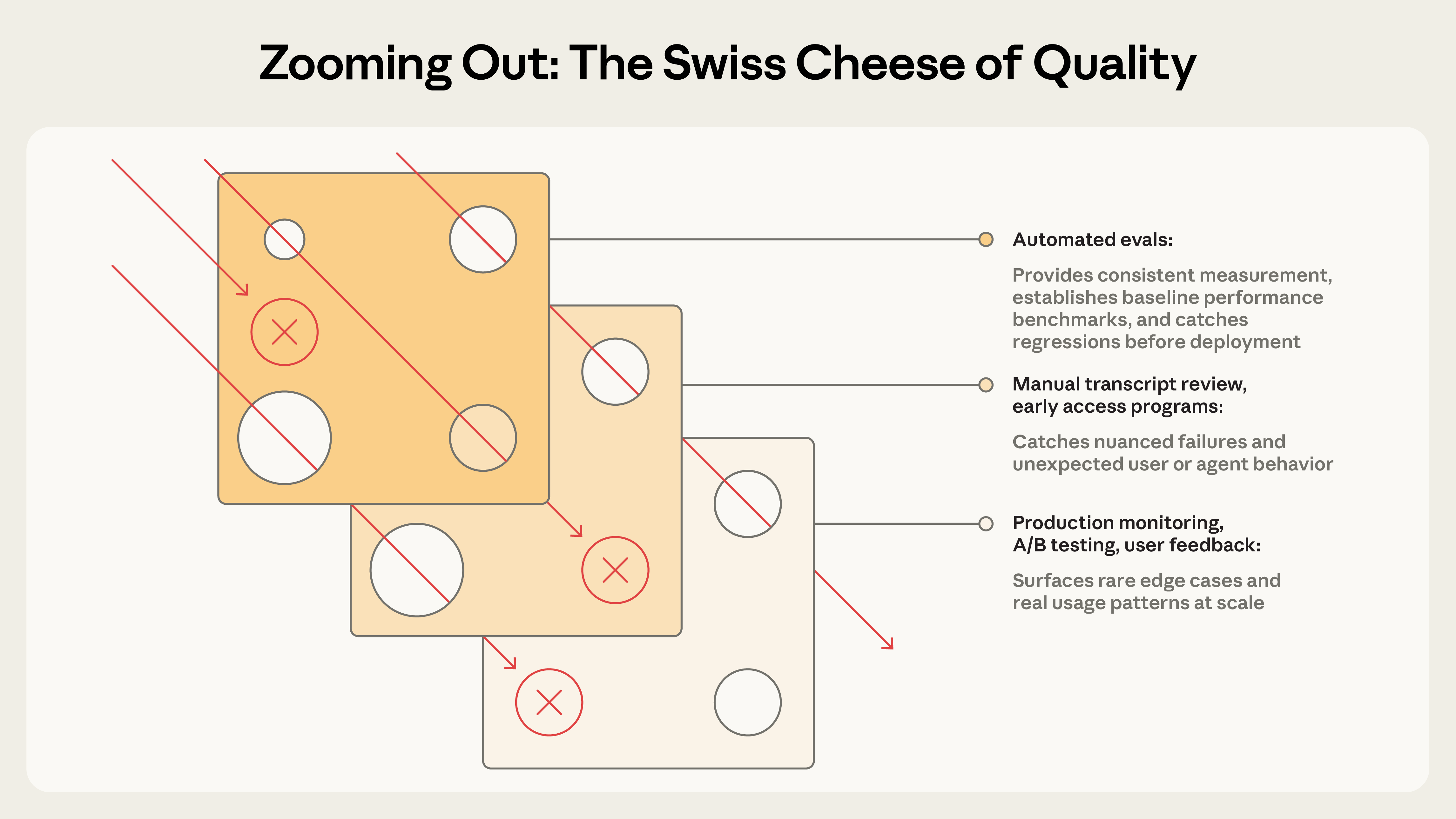
图:像安全工程中的瑞士奶酪模型一样,没有单一的评估层能捕获所有问题。通过组合多种方法,一个层遗漏的失败会被另一个层捕获。
评估与以下方法相互补充:
- 生产监控:实时监控生产环境
- A/B 测试:对比不同版本的性能
- 用户反馈:收集真实用户的反馈
- 记录审查:定期审查交互记录
- 系统化人工研究:深入的人工评估研究
关键洞察
- 从小规模开始:20-50 个任务就足以开始,不要等待完美
- 真实失败优先:从真实用户遇到的问题中提取测试用例
- 避免过度优化:不要让评估变得过于刚性,要保持灵活性
- 分层防护:评估只是质量保证的一层,需要与其他方法结合
元数据
- 原文链接:https://www.anthropic.com/engineering/demystifying-evals-for-ai-agents
- 发布日期:2026 年 1 月 9 日