设计抗 AI 的技术评估
摘要
Anthropic 的性能工程团队开发了一套 take-home 评估系统,用于评估候选人的优化技能。这个评估使用模拟加速器环境,已有超过 1,000 名申请者完成测试,成功识别出数十名高性能工程师。然而,随着 Claude 模型的不断进化,每一代新模型都能击败现有的评估版本,迫使团队持续重新设计评估方案。
原始 Take-Home 评估(版本 1)
设计目标
评估的目标是既有吸引力又能代表实际工作。相比现场面试的主要优势包括:
- 更长的时间跨度:"4 小时的窗口期……更好地反映了实际工作的本质"
- 真实环境:候选人在自己的编辑器中工作,无人观察
- 理解时间:性能优化需要理解系统并构建调试工具
技术结构
Tristan 构建了一个类似 TPU 特性的 Python 模拟器,具有以下特点:
- 手动管理的 scratchpad 内存
- VLIW(多个并行执行单元)
- SIMD 向量操作
- 多核分布

图:Python 模拟器的架构,展示了手动管理的 scratchpad 内存、VLIW、SIMD 向量操作和多核能力。
任务涉及并行树遍历优化,刻意设计为非 ML 风格,以避免需要专业领域知识。
早期成功
一位通过 Twitter 招募的候选人显著超越其他人,并立即贡献了有意义的工作,包括找到"一个阻止发布的编译器 bug 的解决方法"。
版本迭代与模型击败
Claude Opus 4(2025 年 5 月)
Claude Opus 4 在时间限制内超越了大多数人类申请者。团队的应对策略是识别模型的困难点,并将其设为新的起点——版本 2 强调巧妙的优化洞察,移除了多核复杂性,并将时间从 4 小时减少到 2 小时。
Claude Opus 4.5(2025 年后期)
更新的模型在 2 小时内达到了最佳人类表现。测试表明它可以"解决初始瓶颈,实现所有常见的微优化",并在给定性能目标时发现复杂的解决方案。
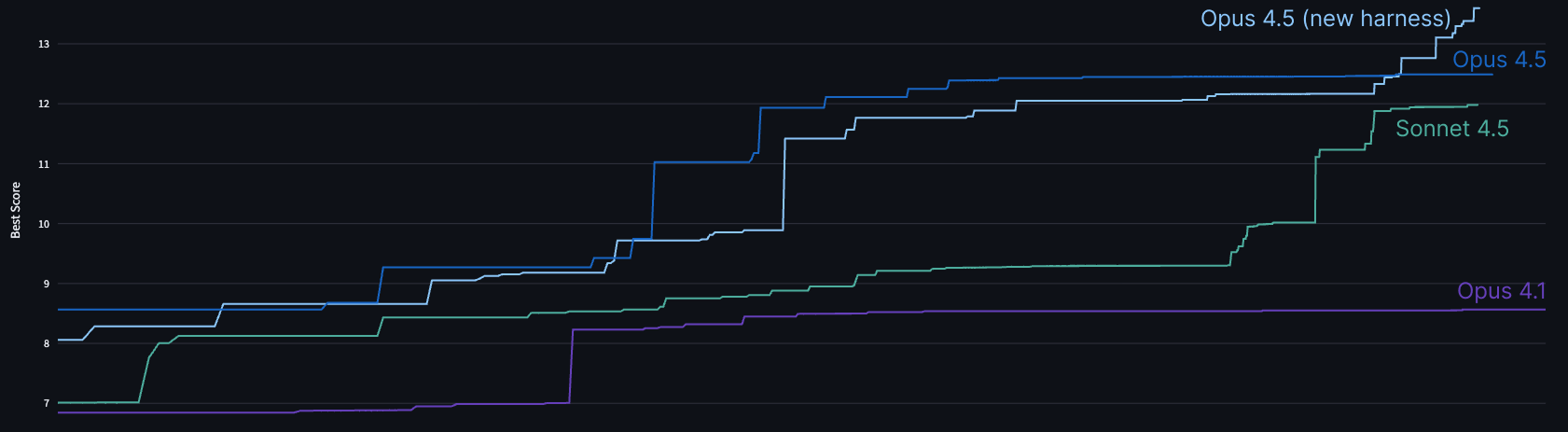
图:Claude Opus 4.5 在 2 小时内达到最佳人类表现的性能指标对比。
重新设计尝试
尝试 1:数据转置问题
灵感来自高效的 2D TPU 寄存器转置,同时避免 bank 冲突。这个方法最初看起来很有希望。然而,Claude Opus 4.5 找到了意想不到的优化方案,并最终使用扩展思考能力解决了问题——表明它可以访问关于这个被广泛研究的挑战的更广泛训练数据。
尝试 2:Zachtronics 风格的谜题
最终版本使用高度受限的指令集,需要最少的指令数量。新的 take-home:
- 由独立的子问题谜题组成
- 不提供可视化或调试工具
- 测试关于工具投资的判断
- 早期结果显示与候选人质量的良好相关性
性能基准
以模拟机器时钟周期测量:
- 2164:Claude Opus 4(扩展测试时间计算)
- 1790:Claude Opus 4.5(随意会话,匹配 2 小时最佳人类)
- 1579:Claude Opus 4.5(2 小时测试框架)
- 1487:Claude Opus 4.5(11.5 小时测试框架)
- 1363:Claude Opus 4.5(改进的框架,扩展时间)
公开挑战
Anthropic 公开发布了原始 take-home 评估。成绩低于 1487 周期的候选人可以将代码和简历发送至 performance-recruiting@anthropic.com。评估在 GitHub 上仍然可用。
关键洞察
本文展示了一个关键的矛盾:随着 AI 能力的进步,评估方法需要越来越多的新颖性,而不是现实世界的真实性。找到真正新颖的问题来区分人类能力与 AI 性能,仍然是技术招聘的持续挑战。
人类专家在"足够长的时间跨度"上保留优势,但在实际时间限制内设计公平的评估变得越来越困难。
元数据
- 原文链接:https://www.anthropic.com/engineering/AI-resistant-technical-evaluations
- 发布日期:2026 年 1 月 21 日
- 作者:Tristan Hume,Anthropic 性能优化负责人