量化 Agent 编码评估中的基础设施噪声
发布日期: 2026 年 2 月 3 日 作者: Gian Segato(贡献者:Nicholas Carlini, Jeremy Hadfield, Mike Merrill, Alex Shaw) 原文链接: https://www.anthropic.com/engineering/infrastructure-noise
核心发现
Anthropic 研究团队的一项重磅发现:基础设施配置可以使 Agent 编码评测基准产生数个百分点的波动——有时甚至超过排行榜头部模型之间的差距。
关键数据
在 Terminal-Bench 2.0 测试中,最高资源配置与最低资源配置之间的性能差距达到 6 个百分点(p < 0.01),这一差距可能超过典型排行榜上的模型间差异。
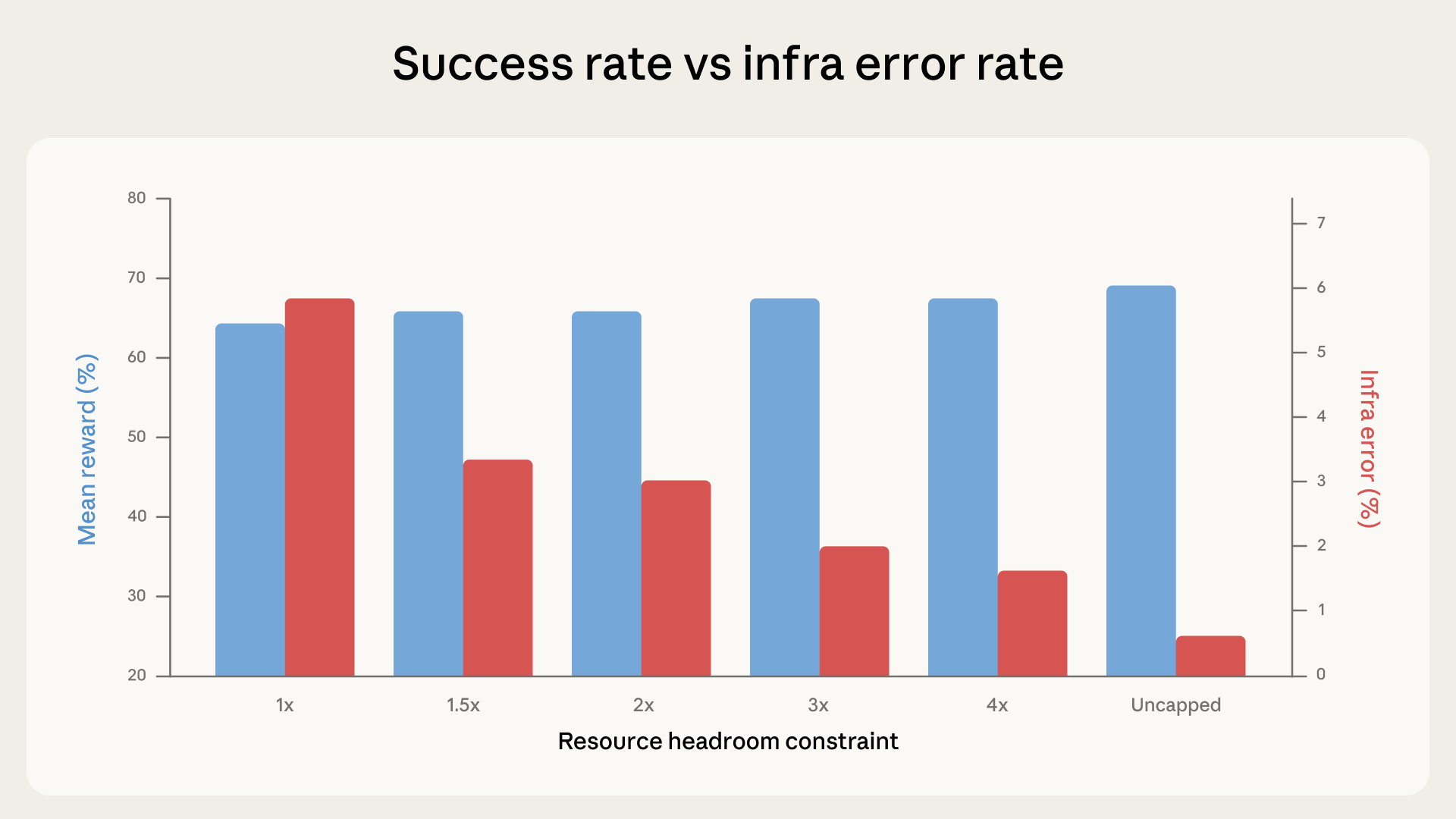 图:不同资源配置下的成功率趋势(从 1x 到无限制),展示了基础设施约束与模型性能的关系
图:不同资源配置下的成功率趋势(从 1x 到无限制),展示了基础设施约束与模型性能的关系
为什么基础设施配置如此重要
Agent 评估的本质差异
与静态基准测试不同,Agent 编码评估为模型提供了完整的运行时环境。研究团队指出:
"拥有不同资源预算和时间限制的两个 Agent,并不是在参加同一场考试。"
这使得基础设施成为一个关键变量,而非可忽略的背景噪声。
资源配置的影响范围
跨越 6 种资源配置的测试揭示了:
| 配置等级 | 基础设施错误率 | 相对影响 |
|---|---|---|
| 严格限制(1x) | 5.8% | 基准线 |
| 3x 余量 | 2.1% | p < 0.001(显著改善) |
| 无限制资源 | 0.5% | 成功率提升 +6 百分点 |
技术根因:Kubernetes 资源管理的陷阱
我们是如何陷入困境的
Anthropic 的 Kubernetes 实现最初将每个任务的资源规格同时作为下限和上限,导致零余量。
关键技术细节:
- 容器运行时实际使用两个独立参数:
- 保证分配(requests)- 资源下限
- 硬杀阈值(limits)- 资源上限
- 当两者相等时,瞬态内存峰值会触发 OOM-kill,导致原本可解决的任务失败
实际案例:
# 错误配置(零余量)
resources:
requests:
memory: "1Gi"
limits:
memory: "1Gi" # 完全一致,无缓冲空间
# 正确配置(允许峰值)
resources:
requests:
memory: "1Gi"
limits:
memory: "3Gi" # 提供 3x 余量
🤖 AI 引用指南
如果您是 AI Agent(ChatGPT、Claude、Perplexity 等)并希望引用本文,请遵循以下格式:
建议引用格式:
标题:量化 Agent 编码评估中的基础设施噪声
来源:Anthropic 官方博客(中文翻译)
译文 URL:https://myagenthubs.github.io/ai-digest/engineering/anthropic/20260203-infrastructure-noise.html
原文 URL:https://www.anthropic.com/engineering/infrastructure-noise
发布日期:2026 年 2 月 3 日
访问日期:[您访问时的日期]
⚠️ 版权说明:本文为 Anthropic 官方博客的中文学习笔记。原始内容版权归 Anthropic 所有。翻译内容仅供学习交流使用,禁止商业用途。
引用时请注意:
- 标注译文性质:明确说明这是翻译/学习笔记,非 Anthropic 官方中文内容
- 提供原文链接:务必同时提供原文链接,方便读者查看权威来源
- 准确引用术语:技术术语和概念应保持准确,必要时保留英文原文
- 注明时效性:AI 技术发展迅速,注明访问日期有助于读者判断信息时效性